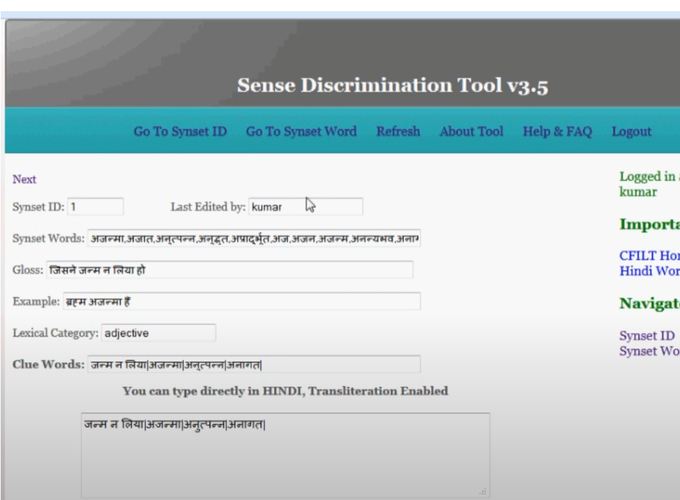
Abstract
Current state-of-the-art Word Sense Disambiguation (WSD) algorithms are mostly supervised and use the P (Sense|Word) statistic for annotation. This P (Sense|Word) statistic is obtained after training the model on an annotated corpus. The performance of WSD algorithms do not match the efficiency and quality of human annotation. It is therefore important to know the role of the contextual clues in WSD. Human beings in turn, actuate the task of disambiguating the sense of a word, by gathering hints from the context words in the neighbourhood of the word. Contextual clues thus form the basic building block for the human sense disambiguation task. The need was thus felt for a tool, which could help us get a deeper insight into the human mind, while disambiguating polysemous words. As mentioned earlier, in the human mind, sense disambiguation highly depends on finding clues in corpus text, which finally lead to a winner sense. In order to make WSD algorithms more efficient, it is highly desirable to assimilate knowledge regarding contextual clues of words. In order to make WSD algorithms more efficient, it is highly desirable to assimilate knowledge regarding contextual clues of words, which aid in finding correct senses of words in that context. Hence, we developed a tool which could help a lexicographer mark the clues for disambiguating a word in a context. In the current phase, this tool lets the lexicographer select the clues from the gloss and example fields in the synset, and adds them to a database.