Recommendation Chart of Domains for Cross-Domain Sentiment Analysis: Findings of A 20 Domain Study
Abstract
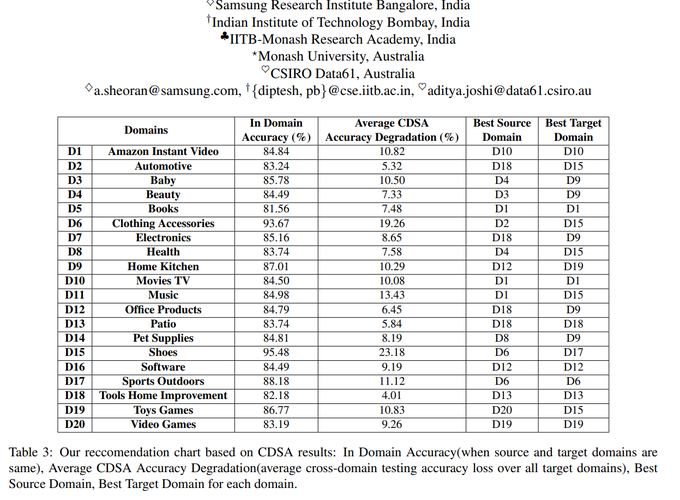
Cross-domain sentiment analysis (CDSA) helps to address the problem of data scarcity in scenarios where labelled data for a domain (known as the target domain) is unavailable or insufficient. However, the decision to choose a domain (known as the source domain) to leverage from is, at best, intuitive. In this paper, we investigate text similarity metrics to facilitate source domain selection for CDSA. We report results on 20 domains (all possible pairs) using 11 similarity metrics. Specifically, we compare CDSA performance with these metrics for different domain-pairs to enable the selection of a suitable source domain, given a target domain. These metrics include two novel metrics for evaluating domain adaptability to help source domain selection of labelled data and utilize word and sentence-based embeddings as metrics for unlabelled data. The goal of our experiments is a recommendation chart that gives the K best source domains for CDSA for a given target domain. We show that the best K source domains returned by our similarity metrics have a precision of over 50%, for varying values of K.